
Figure 1: Qualitative comparison among leading models on reasoning-aware image generation.

Figure 2: Qualitative comparison among leading models on reasoning-aware image generation with multimodal user input.
Recent text-to-image systems face limitations in handling multimodal inputs and complex reasoning tasks. We introduce MindOmni, a unified multimodal large language model that addresses these challenges by incorporating reasoning generation through reinforcement learning. MindOmni leverages a three-phase training strategy: i) design of a unified vision language model with a decoder-only diffusion module, ii) supervised fine-tuning with Chain-of-Thought (CoT) instruction data, and iii) our proposed Reasoning Generation Policy Optimization (RGPO) algorithm, utilizing multimodal feedback to effectively guide policy updates. Experimental results demonstrate that MindOmni outperforms existing models, achieving impressive performance on both understanding and generation benchmarks, meanwhile showcasing advanced fine-grained reasoning generation capabilities, especially with mathematical reasoning instruction.
Figure 1: Qualitative comparison among leading models on reasoning-aware image generation.
Figure 2: Qualitative comparison among leading models on reasoning-aware image generation with multimodal user input.
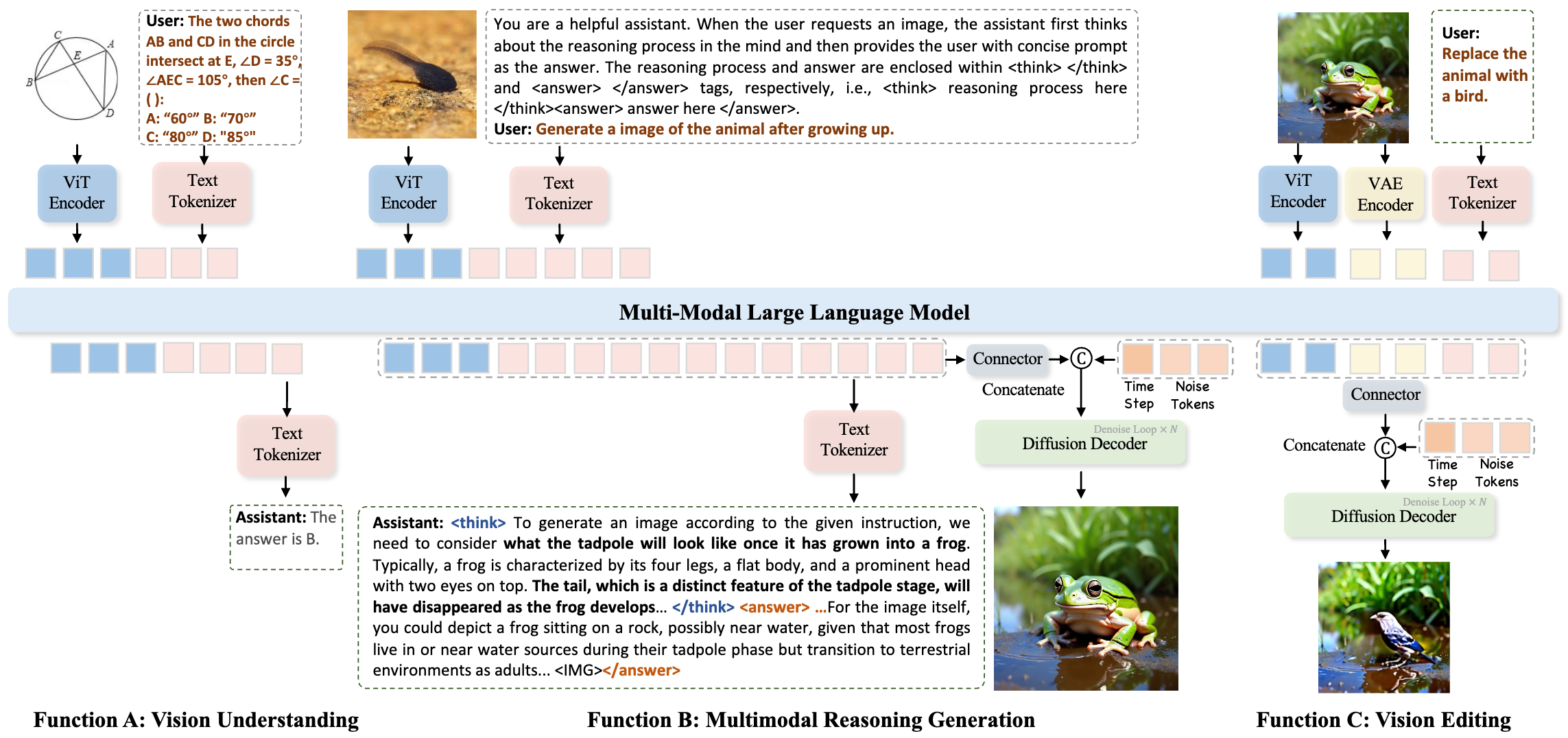
Figure 3: Overview of our inference framework. MindOmni accomplishes vision understanding, multimodal reasoning generation, and vision editing tasks in a unified large model.
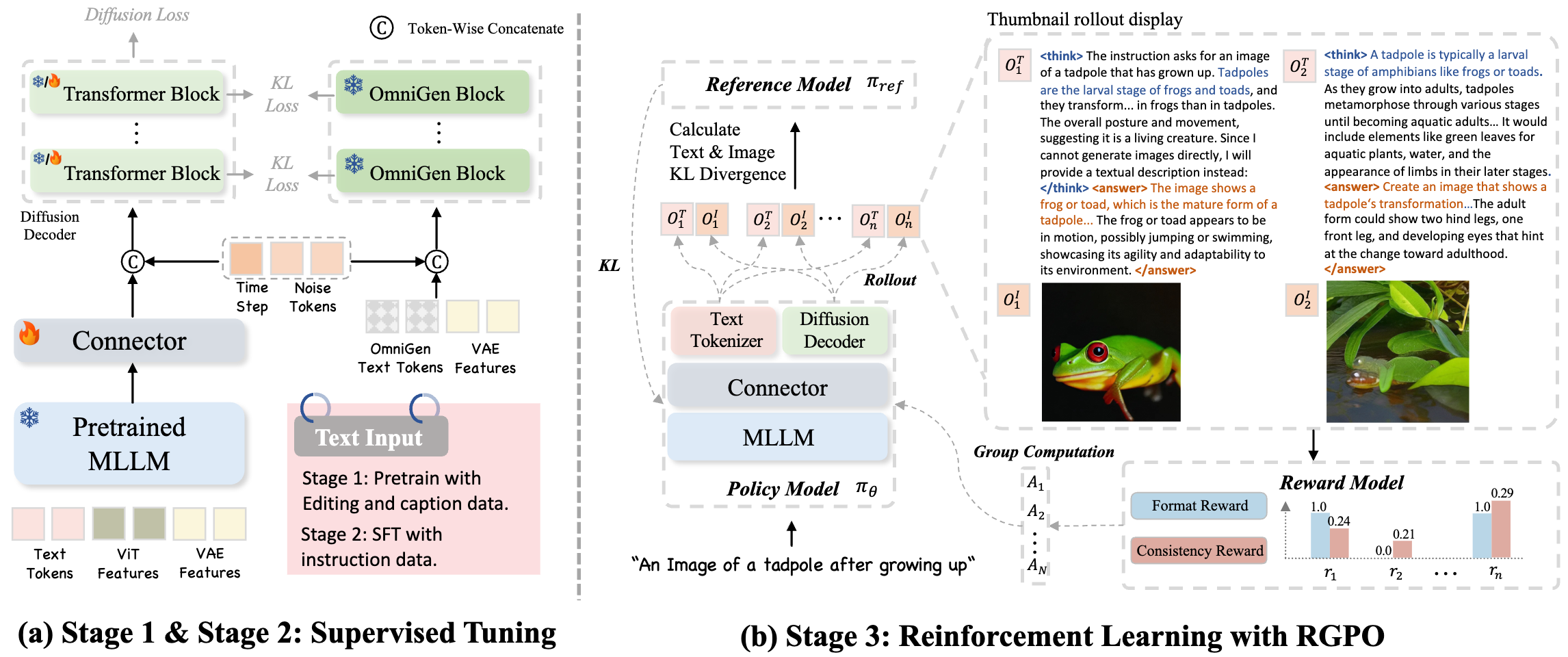
Figure 4: Overview of Training Pipeline. We propose a three-stage training framework comprising pretraining, instruction-based supervised fine-tuning, and reinforcement learning with RGPO.






@article{xiao2025mindomni,
title={MindOmni: Unleashing Reasoning Generation in Vision Language Models with RGPO},
author={Xiao, Yicheng and Song, Lin and Chen, Yukang and Luo, Yingmin and Chen, Yuxin and Gan, Yukang and Huang, Wei and Li, Xiu and Qi, Xiaojuan and Shan, Ying},
journal={arXiv preprint arXiv:2505.13031},
year={2025}
}